Storage options are
extremely important when using a GCP, performance and price wise. I will do a
bit of a non-standard approach for this post. I will first cover the potential
use cases, explain the Hadoop/Standard DB you would use in each case, and then
the GCP option for the same use case. Once that part is done, I will go a bit
deeper into each of GCP Storage and Big Data technologies. This post will
therefore have 2 parts, and an "added value" Anex:
- Which option fits to my use
case?
- Technical details on GCP
Storage and Big Data technologies
- Added Value: Object Versioning and Life Cycle management
1. Which
option fits to my use case?
Before we get into
the use cases, let's make sure we understand the layers of abstraction of
Storage. Block Storage is a typical
storage carried out by applications, data stored in cylinders, UNSTRUCTURED
DATA WITH NO ABSTRACTION. When you can refer to data using a physical address -
you're using Block Storage. You would normally need some abstraction to use the
storage, it would be rather difficult to reference your data by blocks. File Storage is a possible abstraction, and it
means you are referring to data using a logical address. In order to do this,
we will need some kind of layer on top of our blocks, an intelligence to make sure that
our blocks underneath are properly organized and stored in the disks, so that
we don't get the corrupt data.
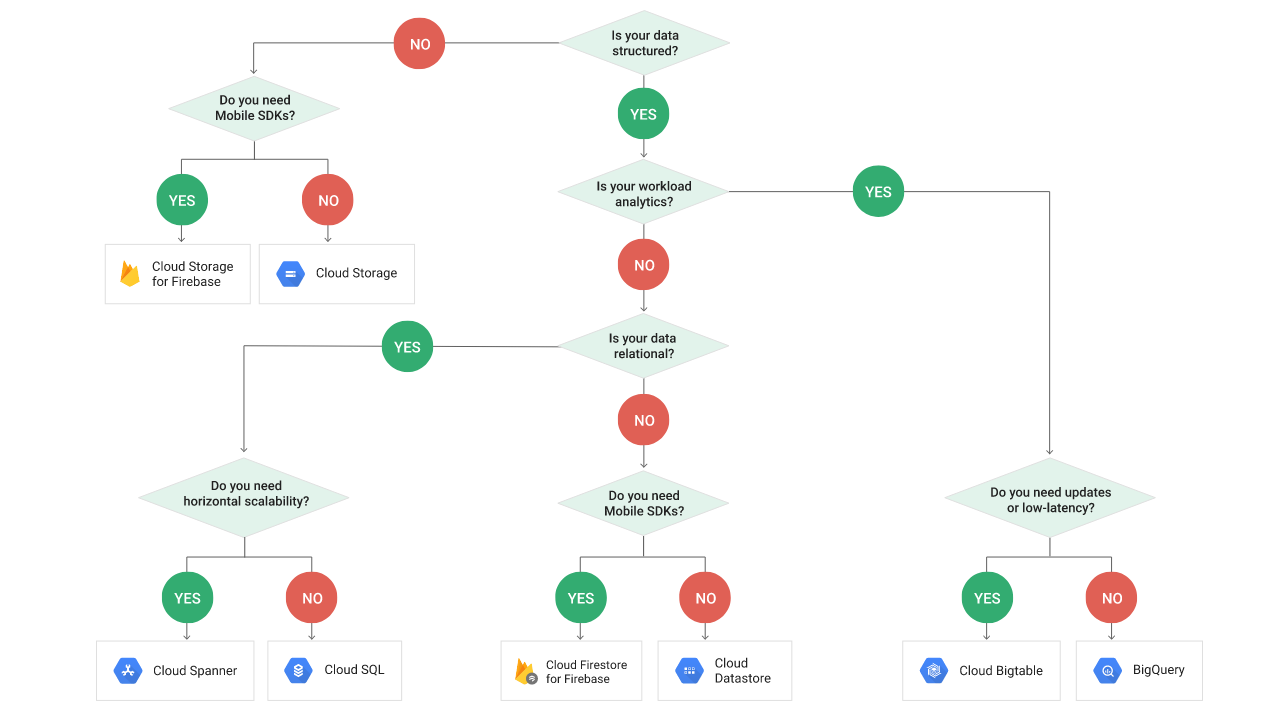
Let's now focus on
the use cases, and a single question - what kind of data do you need to store?
If you're using
Mobile, the you will be using a slightly different data structures:
Let's now get a bit
deeper into each of the Use Cases, and see what Google Cloud can offer.
- If you need Block
Storage
for your compute VMs/instances, you would obviously be using a Googles IaaS option called
Compute Engine (GCE), and you would create the Disks using:
- Persistent disks (Standard or
SSD)
- Local SSD
- If you need to store an
unstructured data, or "Blobs", as Azure calls it, such as Video,
Images and similar Multimedia Files - what you need is a Cloud
Storage.
- If you need your BI guys to
access your Big Data using an SQL like interface, you'll use a BigQuery, a Hive-like Google product.
This applies to cases 3 (SQL interface required), and 7 (OLAP/Data Warehouse).
- To store the NoSQL Documents
like HTML/XML, that have a characteristic pattern, you should use DataStore.
- For columnar NoSQL data, that
requires fast scanning, use BigTable (GCP equivalent of HBase).
- For Transactional Processing,
or OLTP , you should use Cloud SQL (if you prefer open source) or Cloud Spanner (if you need less latency, and horizontal scaling).
- Same like 3.
- Cloud Storage for Firebase is
great for Security when you are doing Mobile.
- Firebase
Realtime DB is
great for fast random access with mobile SDK. This is a NoSQL database,
and it remains available even when you're offline.
2. Technical
details on GCP Storage and Big Data technologies
Storage
- Google Cloud Storage
Google Cloud Storage
is created in the form of BUCKETS, that
are globally unique, identified by NAME, more or less like a DNS. Buckets are STANDALONE, not tied to any Compute or other resources.
TIP: If you want
to use Cloud Storage with a web site, have in mind that you need a Domain
Verification (adding a meta-tag, uploading a special HTML file or directly via
the Search Console).
There are 4 types of
Bucket Storage Classes. You need to be really careful to choose the most
optimal Class for your Use Case, because the ones that are designed not used
frequently are the ones where you'll be charged per access. You CAN CHANGE
a Buckets Storage class. The files stored in the Bucket are called
OBJECTS, the Objects can have the Class which is same or "lower" then
the Bucket, and if you change the Bucket storage class - the Objects will retain their storage class. The
Bucket Storage Classes are:
- Multi-regional, for frequent access from
anywhere around the world. It's used for "Hot Objects", such as
Web Content, it has a 99,95% availability, and it's Geo-redundant.
It's pretty expensive, 0.026/GB/Month.
- Regional, frequent access from one
region, with 99,9% availability, appropriate for storing data used by Cloud Engine
instances. Regilnal class has performance for data intensive computations,
unlike multi-regional.
- Nearline - access once at month at
max, with 99% availability, costing 0.01/GB/month with a 30 day
minimum duration,
but it's got ACCESS CHARGES. It can be used for data Backup, DR or
similar.
- Coldline - access once a year at max,
with same throughput and latency, for 0.007/GB/month with a 90 day
minimum duration,
so you would be able to retrieve your backup super fast, but you would get
a bit higher bill.. At least your business wouldn’t suffer.
We can get a data IN
and OUT of Cloud Storage using:
- XML and JSON APIs
- Command Line (gsutil - a command line tool for
storage manipulation)
- GSP Console (web)
- Client SDK
You can use TRANSFER SERVICE in order to get your date INTO
the Cloud Storage (not out!), from AWS S3, http/https, etc. This tool won't let you get
the data out. Basically you would use:
- gsutil when copying files for the
first time from on premise.
- Transfer
Service when
transferring from AWS etc.
Cloud Storage is not like Hadoop in the architecture sense, mostly because a HDFS architecture requires a Name Node, which you
need to access A LOT, and this would increase your bill. You can read more about Hadoop and it's Ecosystem
in my previous post, here.
When
should I use it?
When you want to
store UNSTRUCTURED data.
Storage
- Cloud SQL and Google Spanner
These are both
relational databases, super structured data. Cloud Spanner offers ACID++,
meaning it's perfect for OLTP. It would, however, be too slow and too many
checks for Analytics/BI (OLAP), because OLTP needs strict write consistency,
OLAP does not. Cloud Spanner is Google proprietary, and it offers horizontal
scaling, like bigger data sets.
*ACID (Atomicity, Consistency, Isolation, Durability)
is a set of properties of database transactions intended to guarantee validity
even in the event of errors, power failures, etc.
When
should I use it?
OLTP (Transactional)
Applications.
Storage
- BigTable (Hbase equivalent)
BigTable is used for
FAST scanning of SEQUENTIAL key values with LOW
latency (unlike Datastore, which would be used for non-sequential data).
Bigtable is a columnar database, good for sparse
data (meaning - missing fields in the table), because similar data is stored next to each other. ACID properties
apply only on the ROW level.
What is columnar
Data Base? Unlike RDBMS, it is not normalised, and it is perfect for Sparse data (tables with bunch of
missing values, because the Columns are converted into rows in the Columnar
data store, and the Null value columns are simply not converted. Easy.). Columnar DBs are also great for the data structures with the Dynamic
Attributes because we can add new columns without changing the schema.
Bigtable is
sensitive to hot spotting.
When
should I use it?
Low Latency,
SEQUENTIAL data.
Storage
- Cloud Datastore (has similarities to MongoDB)
This is much simpler
data store then BigTable, similar to MongoDB and CouchDB. It's a key-value
structure, like structured data, designed to
store documents, and it should not be used for OLTP or OLAP but instead for fast lookup on keys (needle in the
haystack type of situation, lookup for non sequential keys). Datastore is
similar to RDBMS in that they both use indices for fast lookups. The
difference is that DataStore query execution time depends on the size of
returned result, so it will take the same time if you're querying a dataset of
10 rows or 10.000 rows.
IMPORTANT: Don’t use DataStore for Write
intensive data, because the indices are fast to
read, but slow to write.
When
should I use it?
Low Latency,
NON-SEQUENTIAL data (mostly Documents that need to be searched really quickly,
like XML or HTML, that has a characteristic patterns, to which Datastore is
performing INDEXING). It's perfect for SCALING of a HIARARCHICAL documents with
Key/Value data. Don't use DataStore if you're using OLTP (Cloud Spanner
is a better. choice) or OLAP/Warehousing (BigQuery is a better choice). Don't
use for unstructured data (Cloud Storage is better here). It's good for Multi
Tenancy (think of HTML, and how the schema can be used to separate data).
Big
Data - Dataproc
Dataproc is a GCP managed Hadoop + Spark (every
machine in the Cluster includes Hadoop, Hive, Spark and Pig. You need at lease
1 master and 2 workers, and other workers can be Preemptable VMs). Dataproc
uses Google Cloud Storage instead of HDFS, simply because the Hadoop Name Node
would consume a lot of GCE resources.
When
should I use it?
Dataproc allows you
to move your existing Hadoop to the Cloud seamlessly.
Big
Data - Dataflow
In charge of
transformation of data, similar to Apache Spark in Hadoop ecosystem. Dataflow
is based on Apache Beam, and it models the flow (PIPELINE) of data and
transforms it as needed. Transform takes one or more Pcollections as input, and
produces an output Pcollection.
Apache Beam uses the
I/O Source and Sink terminology, to represent the original data, and the data
after the transformation.
When
should I use it?
Whenever you have
one data format on the Source, and you need to deliver it in a different
format, as a Backend you would use something like Apache Spark or Dataflow.
Big
Data - BigQuery
BigQuery is not
designed for the low latency use, but it is VERY fast comparing to Hive. It's
not as fast as Bigtable and Datastore which are actually preferred for low
latency. BigQuery is great for OLAP, but it cannot be used for transactional
processing (OLTP).
When
should I use it?
If you need a Data
Warehouse if your application is OLAP/BA or if you require an SQL interface on
top of Big Data.
Big
Data - Pub/Sub
Pub/Sub
(Publisher/Subscriber) is a messaging transport system. It can be defined as messaging Middleware. The subscribers subscribe
to the TOPIC that the publisher
publishes, after which the Subscriber sends an ACK to the
"Subscription", and the message is deleted from the source. This
message stream is called the QUEUE.
Message = Data + Attributes (key value pairs). There are two types of
subscribers:
- PUSH
Subscriber,
where the Apps make HTTPS request to googleapis.com
- PULL
Subscriber,
where the Web Hook endpoints able to accept POST requests over HTTPS
When
should I use it?
Perfect for
applications such as Oder Processing, Event Notifications, Logging to multiple
systems, or maybe Streaming data from various Sensors (typical for IoT).
Big
Data - Datalab
Datalab is an
environment where you can execute notebooks. It's basically a Jupyter or
iPhython for notebooks for running code. Notebooks are better the text files
for Code, because they include Code, Documentation (markdown) and Results.
Notebooks are stored in Google Cloud Storage.
When
should I use it?
When you want to use
Notebooks for your code.
Need
some help choosing?
If it's still not
clear which is the best option for you, Google also made a complete Decision
Tree, exactly like in the case of "Compute".
3. Added
Value: Object Versioning and Lifecycle Management
Object
Versioning
By default in Google
Cloud Storage If you delete a file in a Bucket, the older file is deleted, and
you can't get it back. When you ENABLE Object Versioning on a Bucket (can only
be enabled per bucket), the previous versions are ARCHIVED, and can be RETRIEVED
later.
When versioning is
enabled, you can perform different actions, for example - use an older file and
override the LIVE version, or similar.
Object
Lifecycle Management
To avoid the
archived version creating a chaos in some point of time, it's recommendable to
implement some kind of Lifecycle Management. The previous versions of the file
maintain their own ACL permissions, which may be different then the LIVE one.
Object Lifecycle
Management can turn on the TTL. You can create CONDITIONS or RULES to base your
Object Versioning. This can get much more granular, because you have:
- Conditions are criteria that must be
met before the action is taken. These are: Object age, Date of Creation,
If it's currently LIVE, Match a Storage Class, and Number of Newer
Versions.
- Rules
- Actions, you can DELETE or Set another
Storage Class.
This way you can get
pretty imaginative, and for example delete all objects older then 1 year, or
perhaps if a Rule is triggered and conditions are met - change the Class of the
Object from, for example, Regional to Nearline etc.