Disclaimer: Some of the materials I used come directly from Nuage technical documentation, which is for some reason not available to the public (and it should be!). If someone from Nokia is reading this, please note that revealing technical information about what your product provides more market, and gives more visibility to your product. I strongly advise you to make as much Nuage documentation public as possible, because if your product is good (and in my opinion - it is), invite bloggers and technical experts to give you feedback, if they feel comfortable with your product, they will feel free sharing it with potential customers.
Before I get deeper into what Nuage VSP is good for, let's make sure we understand the difference between the IaaS, PaaS and SaaS. In order to really get what your company is doing (or should be doing), whether you are a Service Provider (SP), or an Enterprise consuming resources provided by other Service Provider, you need to have a clear distinction of what is handled by whom in each of these architectures. Basically:
- IaaS (Infrastructure as a Service) - SP Provides Network, Compute and Storage, Customer builds OS and Apps
- PaaS (Platform as a Service) - SP also Provides the OS. Who takes tare of the OS Upgrades and other stuff? Good questions… Depends on the PaaS Provider, could be either way.
- SaaS (Software as a Service) - SP owns everything, including the application
Let's start with the basics. We already know what SDN is all about, separating the Control Plane from the Data Plane, and providing a single Management plane that exposes the Northbound APIs. Nuage follows the same concepts. Nuage created a platform called VSP. VSP stands for Virtualized Services Platform, and it does the Orchestration of the Deployment, handling the following Planes:
- Management plane, represented by Nuage Virtual Service Directory (VSD) and the Cloud Management System or CMS (OpenStack, CloudStack etc.)
- Control plane, handled by Nuage Service Controller (VSC)
- Data Plane, handled by a Virtual Router & Switch (VRS)
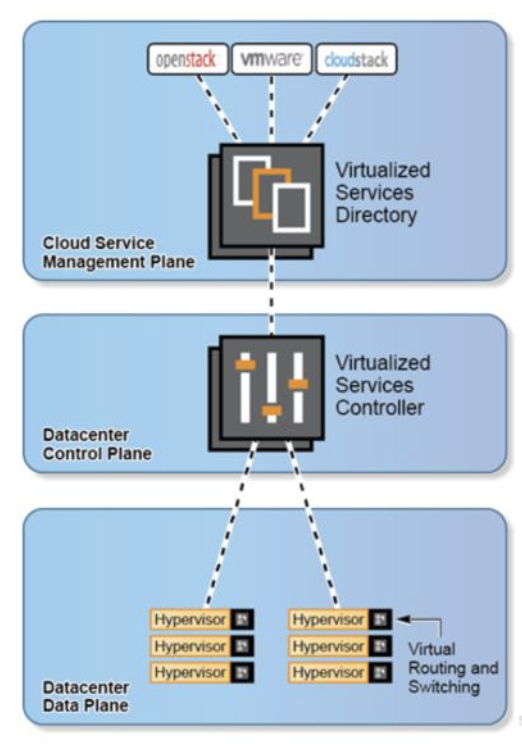
VSP includes the software suite comprising of three key products:
- VSD (Virtual Services Directory), which holds the policy and network service templates.
- VSC (Virtual Services Controller), which is the SDN controller that communicates to the hypervisors.
- VRS (Virtual Routing and Switching) agent that resides within the hypervisor on the server hardware.
Let's now take a deep dive into what communication protocols are deployed between different VSP components:
- Communication between the CMS (Cloud Management System, such as OpenStack, CloudStack, vCenter, vCloud, etc.) and the VSD is done via RESTful APIs. We're talking about the Northbound APIs that allow us to configure Nuage Platform, or VSP.
- Communication between the VSD and VSC is via industry standard XMPP (Extensible Messaging and Presence Protocol), using the Management network. SSL is optional, but recommendable.
- Communication between the VSC and the hypervisors (including the VRS) is via OpenFlow, using the Underlay Network. SSL is again, optional but recommended.
- SDN is all about virtualization, but luckily - physical servers have not been forgotten. To integrate “bare metal” assets such as non-virtualized servers and appliances, Nuage Networks also provides a comprehensive Gateway solution: software-based VRS gateway (VRS-G) and hardware-based 7850 VSG.
I'd recommend you to get acquainted with the individual components of the architecture by reading the rest of this post first, and then re-visit the previous paragraph. It will all make much more sense for you.
Let's now check out individual Nuage VSP components, and see what each one does. Once again, I'll try to be methodical (not an intuitive task for my mind), and try to structure the post, so that you can follow:
- VSD, or the Virtualized Services Directory at the Network Management Plane
- VSC, or the Virtualized Services Controller, at the Network Control Plane
- VRS and VSG , or the Virtualized Routing & Switching and Virtualized Services Gateway, at the network Data Plane
- Security Policies: NFV and Service Chaining
1. VSD - Virtualized Services Directory, holds the Policy and Network Templates. VSD uses XMPP protocol to communicate with VSC.
VSD is where we do the Service Definition by defining Network Service Templates. The service definition includes domain, zone, subnet and policy templates. A domain template can also include policies (e.g. security, forwarding, QoS, etc.) to be applied at the different levels (vPort, subnet, zone, domain). I will cover all these concepts in just a while. It´s an essential component that will manage everything. It can be deployed as a Physical or a Virtual machine. it comes as an OVA file (for ESXi) and QCOW2 file (for KVM), or as an ISO image (recommended for the production environment). You can choose whether you want to do a standalone deployment, or a cluster of 3 VMs. To work properly, VSD requires an NTP server and a DNS server in the network.
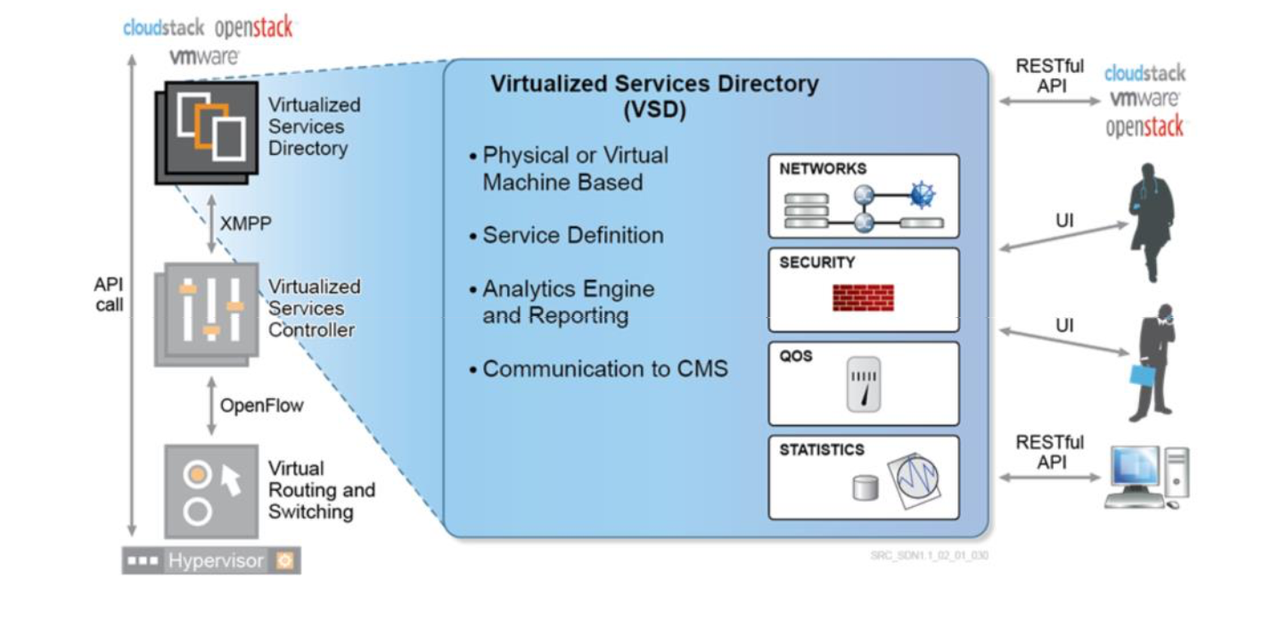
The VSD also contains a powerful analytics engine (optional, based on Elastic Search). The VSD supports RESTful APIs for communicating to the cloud provider’s management systems. In the case of OpenStack, it is between nova and nova-compute, while vCloud uses the vCenter API to access the ESXi HVs.
VSD has two types of users:
Administrator/CSP Users, who will have full visibility into all of the functionality of VSD
Enterprise/Organization Users. An enterprise user belongs to one, and only one, specific enterprise.
TIP: Have in mind that if you're interesting in LDAP, users must be manually created in VSD, even if they have already been created in the LDAP directory.
VSD Service Abstraction - a VSD way of creating an Object Tree, where the Domain is the one Root and Zones, Subnets and another Object have an exact place in the Tree. VSD then translates the Service Abstraction into the Service Instances, following the same Object Tree. Having in mind that domain is mapped to a distributed VPRN instance (dVPRN) while a subnet is mapped to a distributed RVPLS instance (dRVPLS), we are counting with:
- L2 Service Instances (vRVPLS)
- L3 Service Instances (dRVPN)
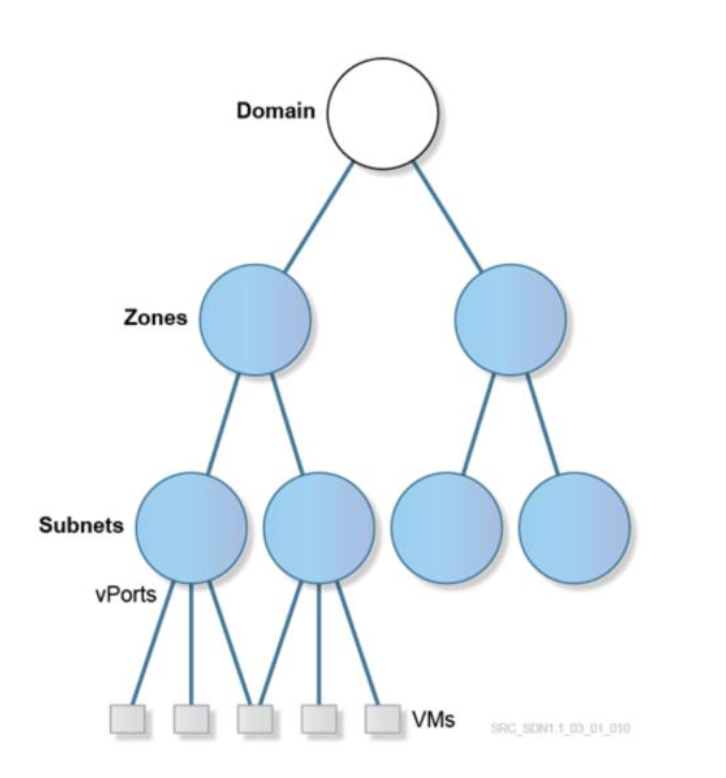
Domain: An enterprise contains one or more domains. A domain is a single “Layer 3” space, which can include one or more subnetworks that can communicate with each other. In standard networking terminology, a domain maps to a VPRN (Virtual Private Routed Network) service instance. Route distinguisher (RD) and route target (RT) values for the VPRN service are generated automatically by default, but can be modified. CSP Root users can create domain template for all the enterprises. Enterprise Administrators and Network Designers group users can create domain templates for their enterprises. Users that belong to other groups cannot create domain templates.
Layer 2 Domain: A standard domain is a Layer 3 construct, including routing between subnets. A Layer 2 domain, however, is a mechanism to provide a single subnet, or a single L2 broadcast domain within the datacenter environment. It is possible to extend that broadcast domain into the WAN, or legacy VLAN.
Zone: Zones are defined within a domain. A zone does not map to anything on the network directly, but instead it acts as an object with which policies are associated such that all endpoints in the zone adhere to the same set of policies.
Subnet: Subnets are defined within a zone. A subnet is a specific IP subnet within the domain instance. The subnet is instantiated as a routed virtual private LAN service (R‐VPLS). A subnet is unique and distinct within a domain; that is, subnets within a domain are not allowed to overlap or to contain other subnets in accordance with the standard IP subnet definitions.
vPorts: Intended to provide more granular configuration than at the subnet level, and also support a split workflow. The vPort is configured and associated with a VM port (or gateway port) before the port exists on the hypervisor or gateway. Ports that connect the Bare Metal Servers to an Overlay are also called vPort. Whenever an vPort is instantiated, an IP address is assigned to it, unique at the Domain level, from the Subnet that the vPort belongs to. VSD is responsible for assigning the correct IP address, regardless if the VM asks for a specific IP (statically configured on the OS), or from a DHCP pool. The same Virtual IP can be assigned to multiple vPorts for redundancy (must be different then any of the IPs assigned to the vPorts).
All ports will have a corresponding vPort, either auto-configured or configured via REST API. Configuration attributes may optionally be configured on the vPort.
VM is formed from its profile, which contains the VM metadata. This metadata defines which Domain, Zone, Subnet and vPort to apply to every vNIC of the VM. It also defines which Enterprise and User Group it belongs to. Additionally, some metadata may be specified if attaching to a specific vPort is required. When a new VM is created, a VM creation request is sent to the VSC from the VRS agent in an OpenFlow message using the Underlay Network. This message contains the VM-related metadata. VSC forwards the request one level higher in the hierarchy, to the VSD in an XMPP message using the Management Network. The VSD receives the VM creation request, reads its metadata and checks them against the policy definitions. The VSD learns the MAC address assigned to this VM from the metadata, and in a VSD managed IP address allocation scenario, it assigns an IP address for it from the subnet (usually the next available IP address).
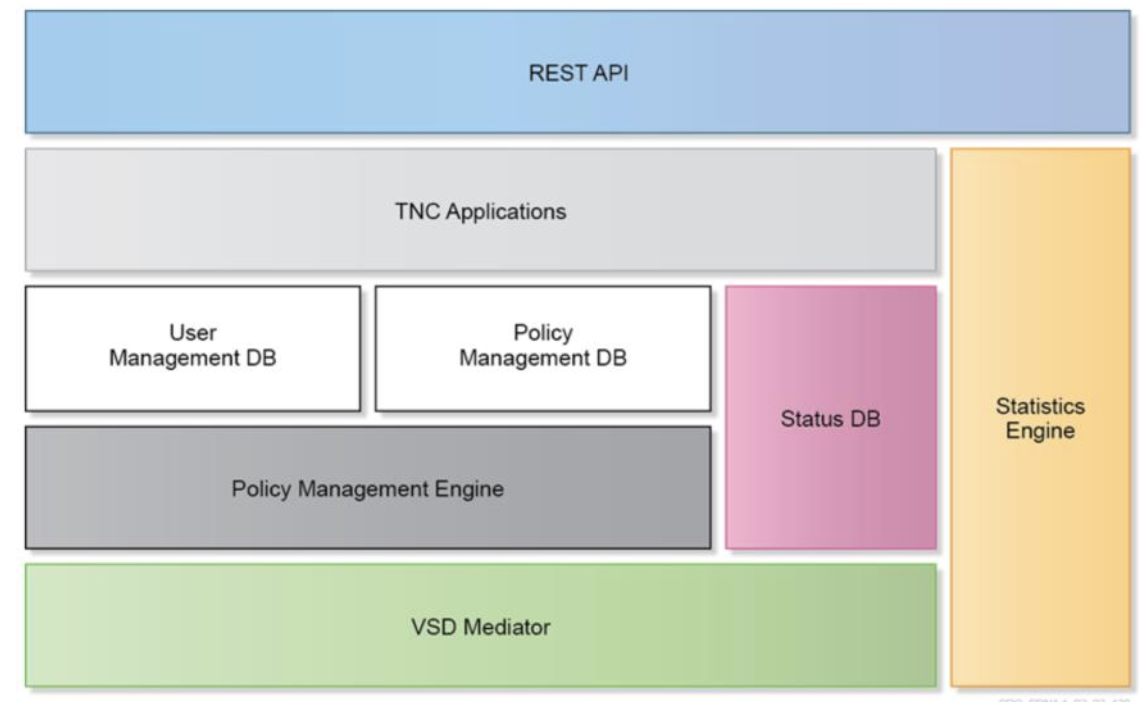
VSD has a somewhat complex architecture. The components of the VSD can be centralized on a single machine or distributed across multiple machines for redundancy and scale. Some of the most important to have in mind at this point are:
- TNC stands for trusted network connect, which is an open architecture for network access control.
- Policy management engine evaluates the policy rules configured on the VSD (Security and QoS policies, IP assignments etc.) It sends policies to VSC based on network events.
- VSD mediator is a VSD Southbound interface used for communication to the VSC. It receives requests for policy information and updates from the VSC, and pushes policy updates to the VSC. The VSD itself is an XMPP client: it communicates with an XMPP server, or server clusters.
- Statistics engine collects fine-grained network information at the VRS, VSC and VM levels. It can collect various packet-based statistics such as Packets in/out, dropped packets in/out, dropped by rate limit etc. It provides an open interface for Nuage and third-party analytics applications. Have in mind that by default, Statistics collection is disabled on the VSD. A separate VSD node running Elastic Search needs to be deployed (can also be deployed as a Cluster).
- REST API is the VSD Northbound interface, which exposes all the VSD functionalities via API calls. It can be used by Nuage CMS plug-ins for integration with many CMSs.
2. VSC - Virtualized Services Controller - SDN Controller, controls the Network, communicates with the Hypervisor and collects the VM related information such as MAC and IP addresses . VSC uses OpenFlow to control the VRS. On each VRS we need to define which VSC is active, and which is standby (you can configure various active VCS for Load Balancing). OpenFlow uses TCP port 6633, and it is used to download actual L2/L3 FIBs to the virtual switch components on the Hypervisor.
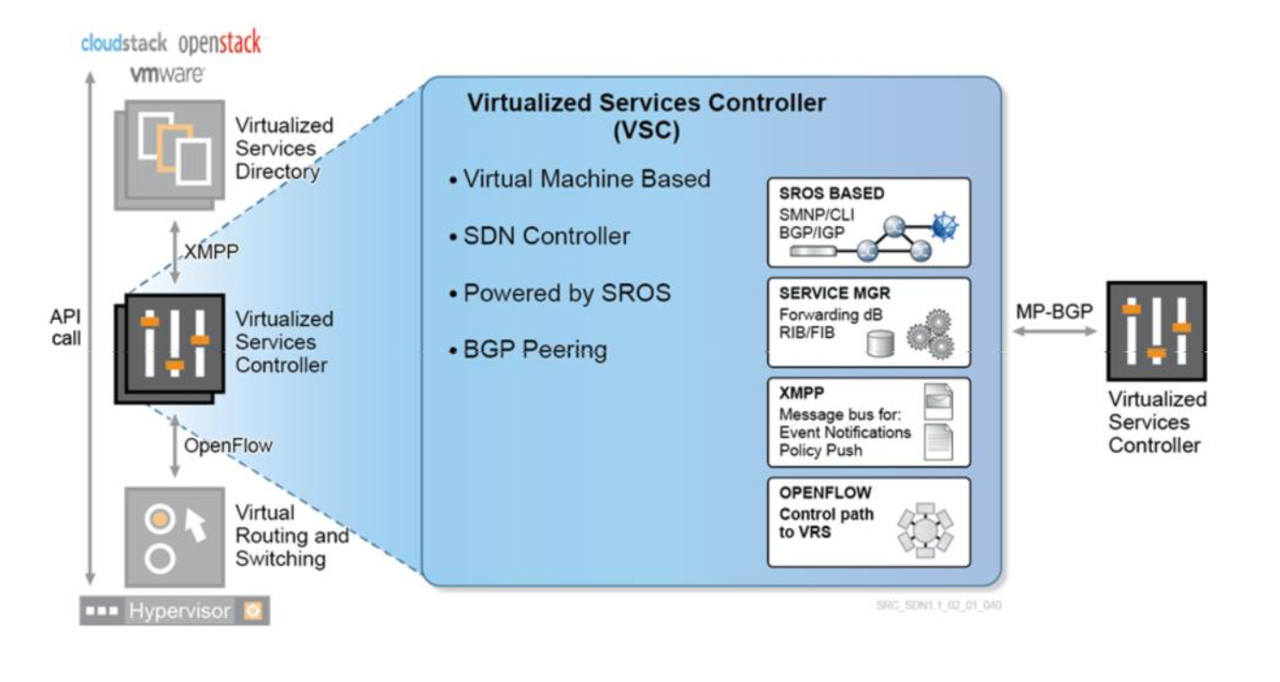
VSC is only installed as a VM (or as an Integrated Module on a Nuage NSG, when NSG is used as VxLAN Gateway), and it comes as OVA file, a QCOW2 file and a VMDK file. VSC has a control interface connected to the Underlay. It is based on Nokia Service Router Operating System (SROS), which is somewhat similar to Cisco IOS (not the same commands, but… intuitive, if you come from Cisco).
Now comes a really cool part about why Nuage. Controllers act like Router Control Plane, and routing is established between VSCs and other routers. This makes is so much easier to implement DCI. VSC needs a routing protocol to exchange the routes with the other VSCs. It can be ISIS, OSPF or Static Routes. MP-BGP EVPN also needs to be established between all the VSCs.
The VSC has three main communication directions:
Northbound: to the VSD via XMPP
East/West: federation functions to other VSCs or IP/MPLS Provider Edge nodes via MP-BGP
Southbound: to the VRSs via OpenFlow
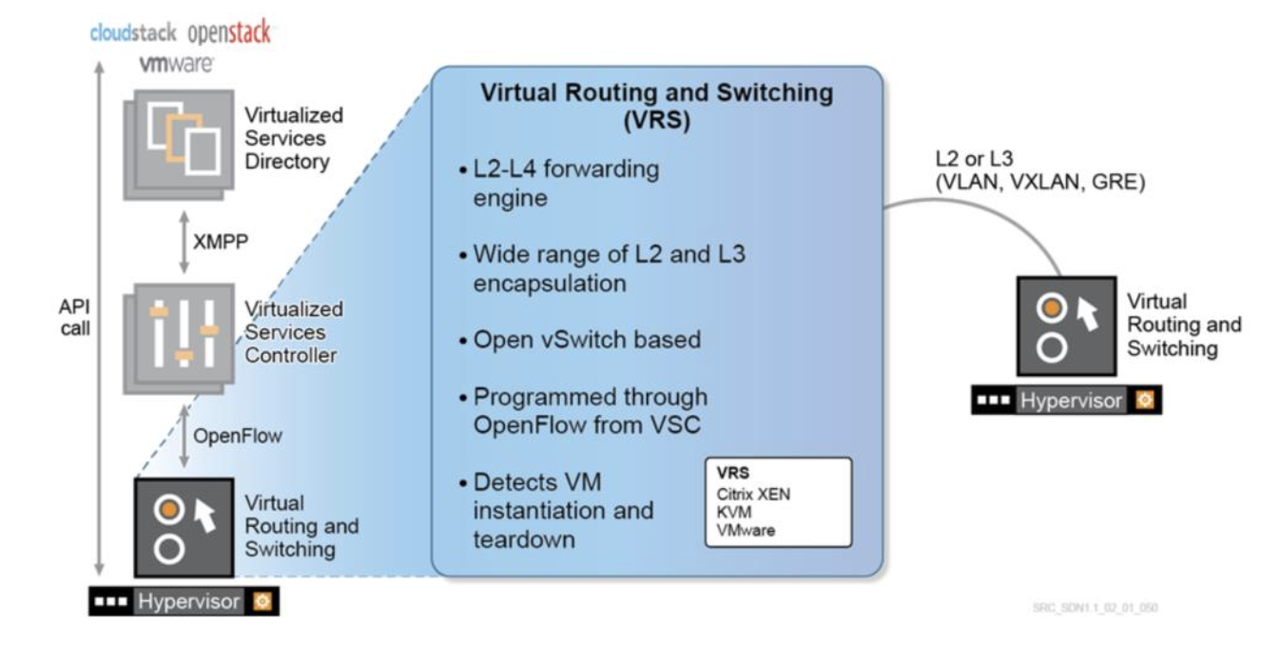
3. VRS (Data Plane) - Virtual Routing and Switching plugin inside the Hypervisor. It´s based on OVS, and it´s responsible for L2/L3 forwarding, encapsulation.
On VRS you can define various VSC for redundancy and load balancing (one active and one standby), and each of them establishes an OpenFlow session using the Underlay network, not Management , using TCP port 6633 (SSL is optional).
VRS includes two main Nuage components:
- VRS Agent, that talks to VSC using OpenFlow. It's responsible for programming L2/L3 FIBs, and it replies to all ARP (no flooding). It also reports changes in VMs to the VSC. The forwarding table is pushed to VRS from VSC via OpenFlow. It has not only a view of all the IP and MAC addresses of the VMs being served by the local hypervisor, but also those which belong to the same domain (L2 and L3 segments), that is, all possible destinations of traffic for the VMs being served by that HV.
- Open vSwitch (OVS), provides Switching and Routing components and Tunneling to forward the traffic.
VRS supports a wide range of L2 and L3 encapsulation methods (VXLAN, VLAN, MPLSoGRE) so that it can communicate with a wide range of external network endpoints (other hypervisors, IP- or MPLS-based routers).
Let's get even deeper into the connection between the Control Plane and Data Plane, or VSC and VRS in Nuage Language. Nuage Networks uses Open Source components, such as libvert, OVS and OpenFlow. Nuage Networks makes use of the libvirt library in the VRS component that runs in Linux-based hypervisor environments (Xen and KVM) to get VM event notifications (new VM, start VM, stop VM, etc.). Libvirt is a package installed on the Hypervisor. Nuage also installs Nuage VRS. This enables the usage of User space tools:
- Virt-Manager: For GUI
- Virsh: Commands (CLI)
Before we continue, let's make sure we understand the basic concepts needed to understand the VRS and VGS (VRS-G included). Basically we need to understand:
- What is OVS (Open virtual Switch).
- Difference between the Underlay and the Overlay.
- What is VxLAN, what are VTEPs, and how it all works.
Open vSwitch (OVS) is a major building block for Nuage SDN. It implements a L2 bridge includingu MAC learning. . OpenFlow is used to configure the vSwitch. It's used for Linux Networking and it's part of Linux Kernel, now used instead of Linux Bridge. OVS can be configured via CLI, OpenFlow or OVSDB management protocol. OVS doesn’t work like VMware VDS or Cisco 1000v. Instead, it only exists on each individual physical host, and it makes it easier for developers of virtualization/cloud management platforms to offer distributed vSwitch capabilities. In Nuage, OpenFlow is used to program the virtual switch within the hypervisor, with the vSwitch becoming the new edge of the datacenter network. The OVS becomes the access layer of the network. The access is where control policies are typically implemented: ACLs, QoS policies, monitoring (netflow, sflow), OVS has these features, and also provides an SDN programmatic interface (OpenFlow and OVSDB management).
The three main components of OVS are:
- ovsdb-server is the configuration database which contains details about bridges, interfaces, tunnels, QoS, etc.
- OVS kernel module handles the data path, including packet header handling, table lookup and tunnel encapsulation and decapsulation. The first frame of a flow goes to ovs-vswitchd to make the forwarding decision; the following frames are then processed by the kernel.
- ovs-vswitchd matches the first frame for a “flow” action (L2 forwarding, mirroring, tunneling, QoS processing, ACL filtering, etc.) and caches these in the flow table in the kernel module.
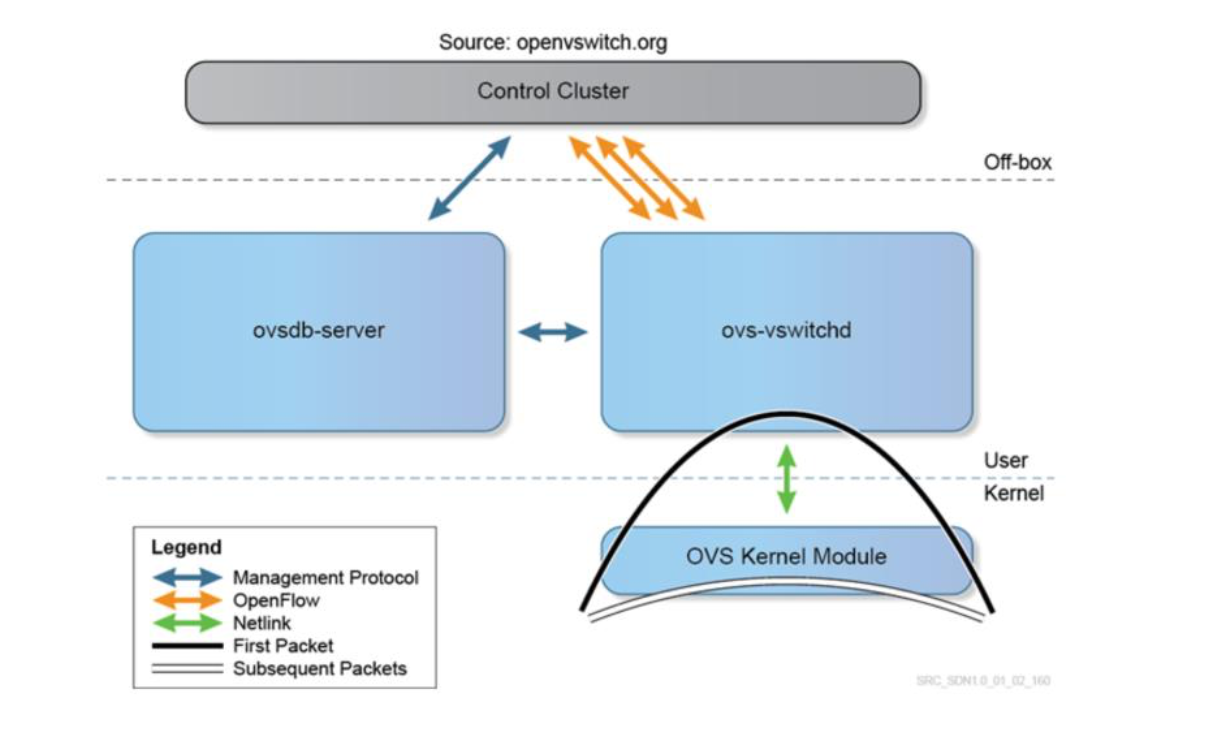
The Open vSwitch is configured by the “control cluster” through a combination of the following methods:
- SSH and the CLI can be used to manually configure the switch locally
- The OVSDB management protocol is used to create switch instances, attach interfaces and define QoS and security policies.
- OpenFlow is used to establish flow states and the forwarding tables for these flows
- Netlink is the Linux communication API used between kernel and user space
Open vSwitch can also be implemented on hardware switches, for example an SDN white box switch, as OVSDB management protocol is also implemented on some vendors’ switches.
Overlay Network: Virtual abstraction built on top of a Physical Network. There are Network-Centric overlays (VPLS, TRILL, Fabric Path) where hosts are not aware of the Overlay, and Host-Centric (VxLAN, NV-GRE, STT) where hosts help create the virtual tunnels.
VxLAN: You can check out my previous posts (go to Blog Map) for more details on how VxLAN Control Plane and Encapsulation take place. VXLAN has a 24 bit VXLAN identifier, which allows for 16 million different tenant IDs. The VXLAN UDP source port is set on the sending side with a special hashing function that allows for load balancing of traffic by ECMP (equal cost multiple path) in the datacenter network. Destination Port is 4789. On the data plane, each VTEP capable device needs to have a forwarding table with each possible destination MAC address within the same L2 domain and the hypervisor hosting it. The VNI identifies the L2 domain within the DC.
More and more server NIC cards support VXLAN offload functionality, which improves the encapsulation/decapsulation performance.
All VTEPs (Virtual Tunnel End Points) in the VxLAN Control Plane need at least the IP connectivity. VTEP needs to act as the default gateway for all the subnetworks that its hosted VMs belong to. In order to do this, VTEP will be assigned a MAC address and an IP address within each of such subnetworks. The combination of the IP and MAC addresses corresponding to a given VM is known as EVPN prefix. When a packet is sent by a VM to its default gateway, because its final destination is an IP address in a different subnetwork, the VTEP will look into its EVPN route table, swap the destination MAC address (presently pointing to the default gateway) to the MAC address of the VM intended to receive the packet, and send the frame to the VTEP hosting the destination VM using the corresponding VXLAN tunnel.
BGP EVPN is an Address Family that can include both, IP and MAC address for a given end point. Forwarding tables on each hypervisor contain information about all VMs in all subnets (each subnet corresponds to a different EVPN instance). VXLAN tunnels exist to reach these subnets on all the hypervisors. Backhaul VPLS brings optimization and enhanced scaling for the number of EVPN MAC addresses and tunnels. With this optimization, each VRS receives only complete forwarding information related to subnets (EVPNs) locally hosted on itself. Each VRS is still aware of every VM in remote subnets, the hypervisor hosting it and its IP address (but not its MAC address). Consequently, when a VM wants to communicate with another VM in a remote EVPN, the VRS (acting as the default gateway) only has to do a route-table lookup to identify which hypervisor is hosting the relevant IP address. This way, it can use the VXLAN tunnel indicated by the backhaul VPLS to forward the packet. There is no need in this case to find the corresponding VPLS and to do an additional L2 FDB lookup to determine the destination MAC address, as would happen if the subnet were not remote.
VRS is in the Underlay Network, and OVS is in the Overlay Network. All Hypervisors need at lease one interface connected to the Underlay Network. You can also have the VTEP assigned to the ToR Switch instead of a Hypervisor, but the concepts don't change.
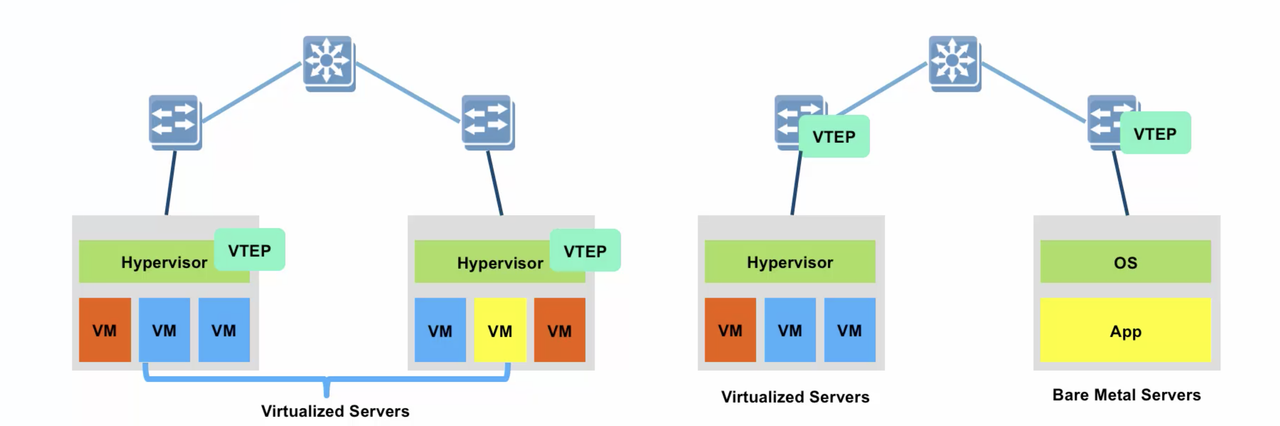
VSG - Virtual Services Gateway allows the interconnection between Physical and Virtual domains. It basically translates VLAN to VxLAN (VxLAN towards Nuage Overlay, and VLAN to Legacy Infrastructure). There are two Nuage versions (physical and virtual), and a version for the "White Boxes":
- Software (VRS-G) which offers Network ports via Overlay (VxLAN) and access ports to the traditional network (VLAN)
- Hardware, 7850 VSG is a 10/40G Switch providing VTEP GW functionality (VTEP in Hardware).
- Hardware VTEP on a White Box
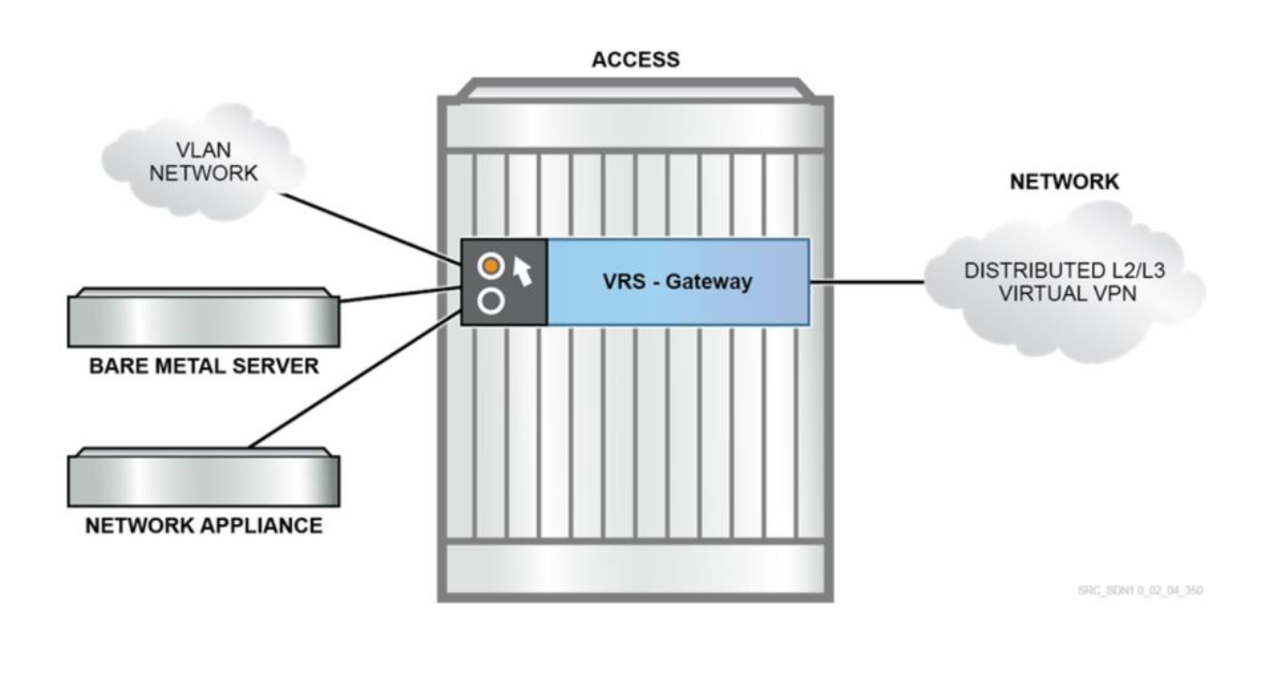
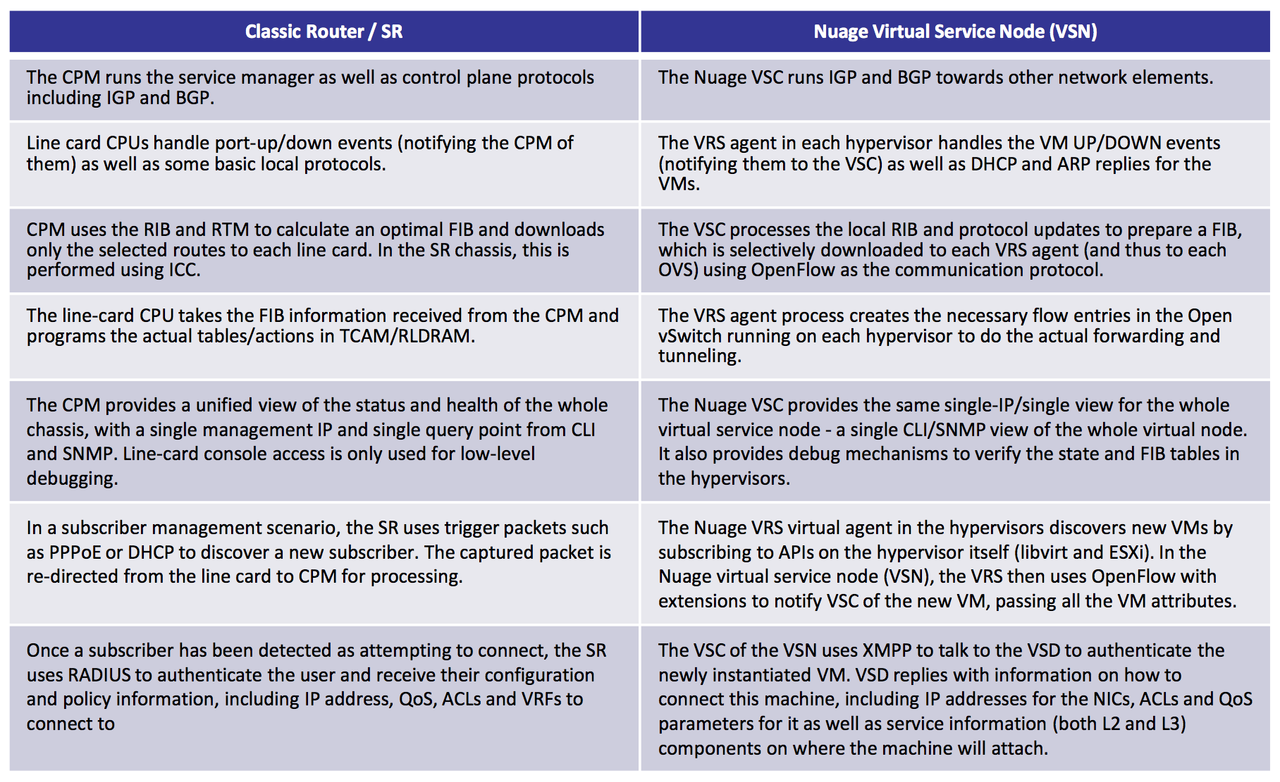
VSN is a Virtual Service Node, composed of VSC and a group of VRS. VSC is like a Control Plane, and VRS are like a Hypervisors. The VSN provides the network operator with a unified view of all the elements being handled by it, making HVs appear as line cards in a chassis when compared to a classic router. It provides a one-stop management and provisioning point for all the HVs under the VSN control.
4. Don’t forget the Security: NFV and Service Chaining
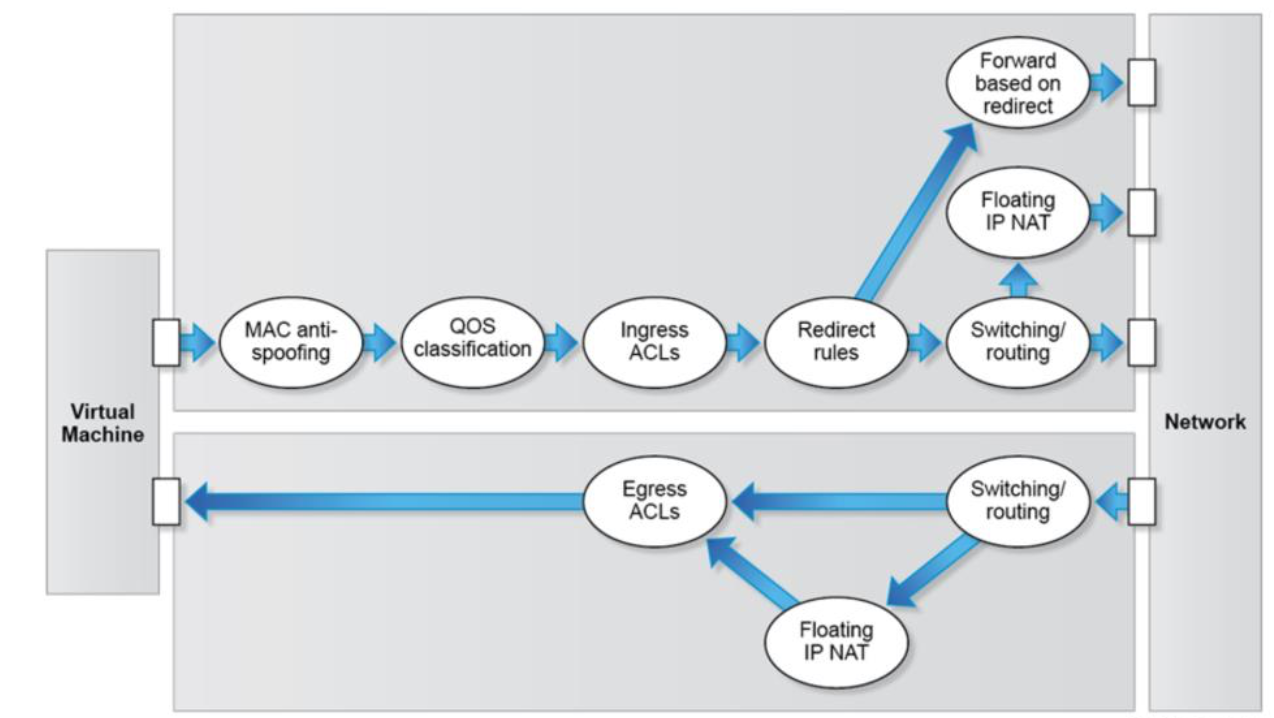
Security Policies are defined at a Domain level, define From/To Zones and/or Subnets. It is important to understand the relative directions of security policies before implementing them. The easiest way to understand the directions is to imagine it from the OVS point of view. This would mean that the INGRESS would me traffic entering the OVS, and Egress - traffic going OUT of the OVS:
Ingress refers to the direction of traffic flow from the VM towards the network (or the OVS component).
Egress refers to the direction of traffic from the network (or the OVS component) towards the VM
Policies have priorities which allows defining the order. They can be Imported/Exported between the Domains, or to/from a File. Before you apply the policies:
By default all INGRESS traffic is dropped (INGRESS means from VM to the OVS).
By default all EGRESS traffic is accepted (from OVS to VM).
When defining the Security Policy, it's important to have in mind Nuage mode of operation, shown on the diagram below.
At the time of creation, a Policy Group Type is assigned to each Security Policy:
Hardware, for hosts and bridge vPort hosted in Nuage VSG/VSA Gateways
Software, VRS and VRS-G hosted vPort, including VM, host and bridge vPort
Important: When you do Stateless, you need ACLs for "returning" traffic. For stateful you just need one policy in one direction.
ACL Sandwich feature enables a network admin to define a supra-list that will drop specific traffic that should NEVER reach the VM. The end user who owns the domain instance can then combine ACL rules into ACLs defined on the domain instance level.
Logging can be able on ACL entry level.
Service Chaining
VSP provides so called Forwarding Policies to control the redirection of packets. This is what later enables Service Chaining. In my opinion, Nuage has the most elegant implementation of Service Chaining of all SDN products out there. All is implemented through flow-based redirection.
Nuage supports Physical and Virtual L4-7 Appliances/Cluster of Appliances as redirection targets, and it gives you the option of creating the Advanced Redirection Policies, where you're given the option to redirect only the traffic destined to a certain TCP/UDP port.




















