Google has made
their Cloud Platform (GCP) so that you can host your application any way your
business requires. When we talk about the traditional Data Center, we tend to
distinguish 3 types of "resources":
- Compute
- Storage
- Networking and Security
In each of these 3
areas, GCP offers you plenty of options. Don't be naive though, you will need
to know the options quite good in order to optimize your performance and costs.
In this 3-part Blog Post I will go into each of these 3 in detail, and hopefully
help you with your decision.
Let's start with the
Compute options. There are 3 options to choose from. You can go for the Google App Engine, or a PaaS option, focus on the
code and let Google handle everything else, use a GCP to simply deploy your VMs
(or Instances as they call it) the way you like, or you can choose the Containers.
My idea is to try and explain each of the options in a bit more details. If
this is something you'd be interested in - keep reading.
What are IaaS and PaaS?
Let's start with a
simple question: What are IaaS (Infrastructure
as a Service), and PaaS (Platform as a
Service) and how are they different from a traditional On-premise/Data
Center model? Back to basics - what does our application need in order to run?
Let's start from the bottom of the Application Stack:
- Networking, to be reached, and to reach data it requires to operate. We need Switches, Routers, etc.
- Storage, to store data. We need Disks, Storage Cabins, SAN switches.
- Servers, to store the compute loads. Physical Servers, with RAM, CPUs etc.
- Virtualization, to optimize the usage of the Physical Resources by using the VMs (Virtual Machines).
- Operating System
- Middleware
- Runtime
- Data
- Applications
In the On Premise
architecture, it is on us to (over-) provision and manage all these resources.
Wouldn't it be great if someone would provision and manage some of the
"basic" layers for us, so that we could focus on the part that
actually matters to our business? THIS is what it's all about. I like how AWS
defines this - in IaaS, the Cloud Provider takes care of all the heavy lifting,
or as they call it - Undifferentiated Services,
while you handle the services on top, that make your business different from
your competitors.
Now, check out the
following diagram, to see what exactly is managed by the Cloud Provider, and
what is managed by You, in the case of IaaS, PaaS and SaaS.

*In some examples
out there, in IaaS OS is partially managed by You. This pretty much depends on
the model that Cloud Provider is offering.
What Compute options does GCP offer?
There are Compute options for hosting your applications in Google Cloud. You can use one of those, or
Mix and Match:
- Google Cloud Functions (currently in Beta). It's a Serverless environment for building and connecting other cloud services. Very simple, very single purpose functions, written in JavaScript, executed in Node.js. Cloud Function executes a response to a TRIGGER event. Functions are not exactly a Compute option, but they do match this use case, so I'll just keep them here.
- Google App Engine (GAE), is the PaaS option, serverless and ops free. It's a flexible, zero ops, serverless platform for highly available apps. You would choose GAE if you ONLY want to focus on writing code. It can be used for the Web sites, Mobile apps, or gaming backend, and also for IoT. Google App Engine is a MANAGED SERVICE, meaning - you NEVER need to worry about the infrastructure, it's invisible to you. There are 2 available environments: Standard (predefined Runtime) and Flexible (configurable Runtime). We will get into these in more detail.
- Google Kubernetes Engine (GKE), is the CaaS/KaaS (Containers/Kubernetes as a Service) option, clusters of machines running Kubernetes and hosting containers. Containers are the auto-contained services, containing all the Libraries and Dependencies, so that you don't have to worry about the Operating System at all. GKE engine allows you to focus on the Applications, not on the OS. You should use it to increase velocity and improve operability by separating the application from the OS. Ideal for Hybrid applications.
- Google Compute Engine (GCE) is the IaaS option, fully controllable down to the OS. We're talking about Instances of VMs. You should use it if you have a very specific requirements from your operating system, or if you need to use the GPUs (yes, this is the only option that let's you add Graphical Processing Units for intensive compute tasks to your Compute resources).
There is also a
fifth option called Firebase, and it's specific for Mobile, but I won't go into
that right now. Instead, let's focus on each of the four options mentioned
above. Each of these options can be used for any application, and it's on you
to choose the one that best fits, each one has their Pros and Cons. Yes, you
can mix them in the same application! Check out the following diagram, to get a
clearer picture:

Google Cloud Launcher
Before we get into
more detail about the Compute options, I'd like to cover the Cloud Launcher,
one of my favorite tools in the GCP. Google Cloud Launcher can help you set up
an easy app, such as WordPress or LAMP stack, in a few minutes. You can customize
your application, because you will have full control of your instances. You
will also know more or less how much everything will cost before you deploy it
all. Remember this for now, because I will be mentioning the Launcher later.
Google Cloud Functions
Floating, serverless
execution environments, for building and connecting the cloud environments. You
would be writing simple, single-purpose functions. When an event that is being watched is fired - Cloud Function is
triggered. You can run it in any standard Node.js runtime. This would be
a perfect option for the coders that like to write their applications in
functions.
Google Application Engine (GAE) - PaaS
PaaS option is a
perfect option if you just want to focus on your code, and you trust Google to
manage your entire infrastructure, including the Operating System. It tends to
be very popular with SW, mobile and Web developers. If you prefer to pay per use, and not per allocation, you might prefer
PaaS (No-Ops) to IaaS (DevOps) option. Also, there's no vendor lock-in,
you can easily move your Apps to another platform because everything is built
on the Open Source tools. App Engine is REAGIONAL, and Google makes sure that
you have the HA using different (availability) zones within the region.
Can you use GAE in Multiple Regions? You cannot
change the region. Your app will be served from the region you chose when
creating the app. Anyone can use the app, but users closer to the selected
region will have lower latency. More details: https://cloud.google.com/appengine/docs/locations
App Engine supports ONLY HTTP/S.
GAE is super easy to
use. You will basically need to create a new Folder, store your files in there, and execute the
command "gcloud app deploy".
That's it!
There are two
environments, depending whether you can customize an OS:
- Standard (deployed in Containers), preconfigured with one of the several available runtimes (specific versions of Java 7, Python 2, Go, PHP). Each runtime includes the standard Libraries. Basically this is a container - Serverless. Your code is running in a Sandboxed environment.
- Flexible (deployed in VM Instances, based on GCE), that you can customize into a non standard environment, and you can use Java 8, Python 3.x, .NET, also supporting Node.js, Ruby, C#. This is not a container, it's a VM of a compute instance, and you are charged based on the usage of the VM instance (CPU, memory, disk usage) that's been provisioned for you. Unlike on GCE, the instances are automatically managed for you, meaning - regional placement, updates, patches and all (root SSH disabled by default, but can be enabled).
IMPORTANT: Scale up time is measured in seconds
in Standard environment, and in minutes in the Flexible environment, simply
because the containers are much faster then the VM instances.
Google Compute Engine (GCE) - IaaS
Google Compute Engine should be used when you
need IaaS, for example, you need to tune your Load Balancing and Scaling. When
you create a VM instance (each instance needs to
belong to a Project, and a Project can have up to 5 VPC - Virtual Private
Networks), you need to choose the Machine Type, a Zone, an Operating
System (Linux and Windows Server are available, you get root access and SSH/RDP
enabled). You can choose one of the following Machine Types, but have in mind
that in order to later change it you need to stop the instance, change it, and
then turn it back on:
- Standard
- High memory
- High CPU
- Shared core (small, non resource intensive)
Compute Engine
instances are pay-per-allocation. When the instance is running, it is charged
at an per-second rate whether it is being used or not. I'd also like to use this
section to clarify a few important concepts related to GCE:
- What is a PREEMPTABLE instance?
- How does Google Maintenance affect your workloads?
- How do I automate instance creation?
- What Disks can I assign to my Instance?
- Which VMs and Images are available for me, and can I qualify for discounts?
What's a Preemptable VM instance?
A type of VM
instance that can be deleted with 30 second notification time, once the SOFT
OFF signal is sent (best practice: you need a SHUT DOWN SCRIPT, able to shut the instance off
and do all the clean-up in less then 30 seconds). It's much cheaper, of course,
because it can be deleted AT ANY TIME (at least
once every 24 hours). It can, for example, be used for the fault
tolerant applications.
How does Google Maintenance affect your workloads?
Google can shut down
your machine for maintenance. You can configure what to do in this case,
migrate or terminate. This is your call, as it directly depends on the nature
of your application, and whether they are Cloud Native (instances treated as a Cattle, rather then as Pets. Confused? Read my previous post for clarification).
Live Migration allows an instance to be up and
running, even in the maintenance state, or during a HW or SW update, failed HW,
network and power grid maintenance etc. The instance is moved to another host
in the same zone. VM gets a notification that it needs to be evicted. A new VM
is selected for migration, and the connection is AUTHENTICATED between the old
and the new VM.
When a Live
Migration is executed there are 3 stages:
- Pre-migration brownout: VM executing on the source, when most of the state is sent from source to target. The time depends on the memory that needs to be copied and similar.
- Blackout: a brief moment when none of the VMs are running.
- Post-migration brownout: a VM is running on the destination/Target Host, but the source VM is still not killed, ready to provide support if needed.
IMPORTANT:
- Preemptable instances cannot be live migrated.
- Live migration cannot be used for the VMs with GPUs.
- Instances with the local SSD can be live migrated.
How do I automate instance creation?
To AUTOMATE the instance creation, you can use the
gcloud command line. One of the options
is for example to assign a LABEL to
instances you want to group (called Instance
Group) in order to monitor or automate. You can get the exact script to,
for example, create an instance, from the graphical interface, just look for
the API and command line equivalents. Yes, this is awesome, you can literally
get an API for any graphical interface action you take. Automation made easy,
good job Google!
DevOps tools are
also available (GCP equivalents for some), which is great if you have strong
DevOps skills in the house:
- Compute Engine Management using Puppet, Chef, Ansible.
- Automated Image Builds with Jenkins, Packer and Kubernetes.
- Distributed Load Testing with Kubernetes.
- Continuous Delivery with Travis CI.
- Managing Deployments using Spinnaker.
What Disks can I assign to my Instance?
You also have loads
of Storage options for your instances. I won't go into the storage options here in detail, but to create a Disk for your VM instance you have 4 options:
- Cloud Storage Bucket, as the cheapest option.
- Standard persistent disks (64 TB).
- SSD persistent disks (64 TB).
- Local SSD (3 TB), actually attached to the instance, in the same Server.
Which VMs and Images are available for me, and how do I qualify for discounts?
Images help you
instantiate new VMs with the OS already installed. There are Standard and Premium
Images, depending whether you need some kind of license, like for RedHat
Enterprise Linux or MS Windows. You should have in mind that you have 2
possibilities to get your image ready to launch:
- Startup Script, that you need to write in order for it to download your dependencies, and prepare everything. It needs to always bring the VM in the same state, regardless how many times you execute it.
- Baking is a more efficient way to create an image in order to faster provision an instance, much more efficient then a Startup script. You would start from the Premium image, and create a Custom instance (sort of a Template, if you will). Baking takes much shorter to provision an instance then a Startup disk. Everything is included into the "baking image". Version management and rollbacks are much easier, you can just rollback an image as a whole.
Check out this link about Google Cloud pricing for more details.
In the image
lifecycle the possible statuses are: CURRENT,
DEPRECATED (can still be used and launched), OBSOLETE (cannot be launched) and DELETED
(cannot be used). This should give you some idea about how you would be
managing your instance versions.
- Snapshots can only be accessed within the same project.
- All machines are charged for at least 1 minute. After that, a per-second payment is applied. The more you use the VM, the more discount you get.
Before we get to the
possible discounts, you first need to choose your machine type correctly, to
optimize the cost and the performance:
- Pre-defined
- Custom: You can specify the number of vCPUs and Memory. You would start with one of the pre-defined, and if you see that your CPU or memory are under-utilized, customize it.
- Shared-core is another option, meant for small, non resource intensive applications, that require BURSTING.
- High Memory Machines: more memory per vCPU, 6.5GB per Core.
- High CPU Machines: more vCPU per unit of memory, 1.8GB per Core
Google offers a few
types of discount/price optimization, among others:
- Sustained use, when you use a VM for a long period of time
- Committed use, that you can purchase in 1 year or 3 year contract, and you get a good price.
- Rightsizing is a feature recommends which size of the VMs to run after analyzing your application behavior. This is a brand new feature, and it relies to the Stackdriver collected information from the past 8 days.
Google Containers/Kubernetes Engine (GKE) - CaaS/KaaS
If you have lots of
dependencies, you would of course benefit most using the Containers. Container
is a light weight standalone executable package that includes everything needed
to run it: code, runtime, system tools, system libraries, settings. Containers
de-couple the Application from the Operating System, and they can reliably run
on different environments. Different containers run on a same Kernel, as
presented in the picture below, taken from the Dockers web page:

Container vs VM
A VM contains an
entire operating system packaged along with the application. A container ONLY
runs an OS Kernel and nothing else, it contains the Application and the
essential Libraries, Binary files etc., and it can easily be moved from one
Physical or Virtual machine that has the Kubernetes engine, to another.
Containers are much faster, as there is no OS to boot, and they are much
smaller in size.

To be precise, using
Containers/Dockers we can achieve:
- Process isolation
- Namespace isolation
- Own Network Interface
- Own Filesystem
Meanwhile, when we
say a Micro service, that simply means that one
container = one process.
What is Kubernetes?
Kubernetes is an
open source Container Manager, originally created by Google for it´s internal
use. Kubernetes automates Deployment, Scaling and Management. This means that
using Kubernetes you can:
- Rollout new features seamlessly
- Auto scale your application
- Run your application in the Hybrid environment, as long as you have the Kubernetes Engine in your VMs.
Why is Kubernetes so
important here? Because Google Kubernetes Engine uses Kubernetes as a Container
Management engine.
Let's first check
out the important components of the Kubernetes
architecture:
- A Container Cluster has one supervising machine running Kubernetes (Master Endpoint, or Master Instance works like Hadoop Cluster Manager). Kubernetes Master manages the cluster, and it's your single point of management of the Kubernetes Cluster.
- Master Instance will be in touch with a number of individual machines using a software called Kubelet, each running Docker.
- Each individual machine running Kubelet is known as a Node Instance.
- Pod is a smallest deployable unit, a group of 1 or more containers in a Node. Inside each Pod in every Node Instance, Containers are running. Pod has it's settings in a Template.
- Replication Controller ensures that specific number of Pod replicas are running across Nodes.
- Services are the abstraction layer that decouples the frontend clients to the backend pods. They define the LOGICAL set of pods across nodes and the way of accessing them. Load Balancing is one of the Services, creating an IP and a port as a connection point to our Pods.
- Label is a METADATA with semantic meaning. It's used for selecting and grouping the objects.
- scheduler is in charge of scheduling pods onto nodes. Basically it works like this: You create a pod,
scheduler
notices that the new pod you created doesn’t have a node assigned to it, and
assigns a node to the pod. It’s not responsible for actually running the pod –
that’s the kubelet’s job. So it basically just needs to make sure every pod has
a node assigned to it.
- kubectl is a CLI tool for Kubernetes.

Google Cloud Engine
includes the following components, most clarified in the Kubernetes
architecture:
- Container Cluster, includes a Kubernetes Master and Compute Engine instances where Kubernetes are running, managing all the components with Kubernetes Master.
- Kubernetes Master, as a single point of management of the cluster.
- Pods, as groups of containers.
- Nodes, as individual Compute Instances.
- Replication Controller, ensuring the defined number of Pods are always available.
- Services, decoupling a frontend client from the backend Pods, providing a Load Balancer with a single URL to access your Backend.
- Container Registry is the image repository, so that you can deploy container images

Why GKE, and not Kubernetes on GCE?
This all depends on
what exactly are your needs. You can use CaaS by Google (GKE), which is easier
out of the box, and Google would manage the entire "Undifferentiated"
application stack, up to Containers. You can also build your own Container management
on top of Googles IaaS (GCE), for example if you need GPUs, or you have some
specific OS needs, or maybe a non-Kubernetes container solution, or if you are
migrating your existing on premise Container solution.
Before you make a
decision to, for example, run Kubernetes directly without something like GKE on
top of it, I strongly recommend you to investigate the following GitHub link,
on implementing Kubernetes without the pre-defined scripts: https://github.com/kelseyhightower/kubernetes-the-hard-way
If you use
containers, the best way would be to use DevOps methodology, and Jenkins for
CI/CD. You can use Stackdriver for
logging and monitoring.
Storage options for
GKE are the same like with the GCE, but Container disks are ephemeral (lasting for a
very short time), so if you do want your data not ephemeral, you need to use an
abstraction called gcePersistentDisk.
When would you use GKE instead of GAE?
GAE only supports
HTTP/HTTPS, so if you need to use any other protocol - you would go for CaaS
rather then App Engine. Also, if you are
using a Multicloud environment, GAE only works on GCP. App Engine doesn't use Kubernetes,
so if you want to use Kubernetes - you would also rather go for GKE.
Interesting fact: Pokemon GO was deployed on
GKE (50x more users connected then expected), while Super Mario Run (launched
at 150 countries at the same time) was deployed on the GAE.
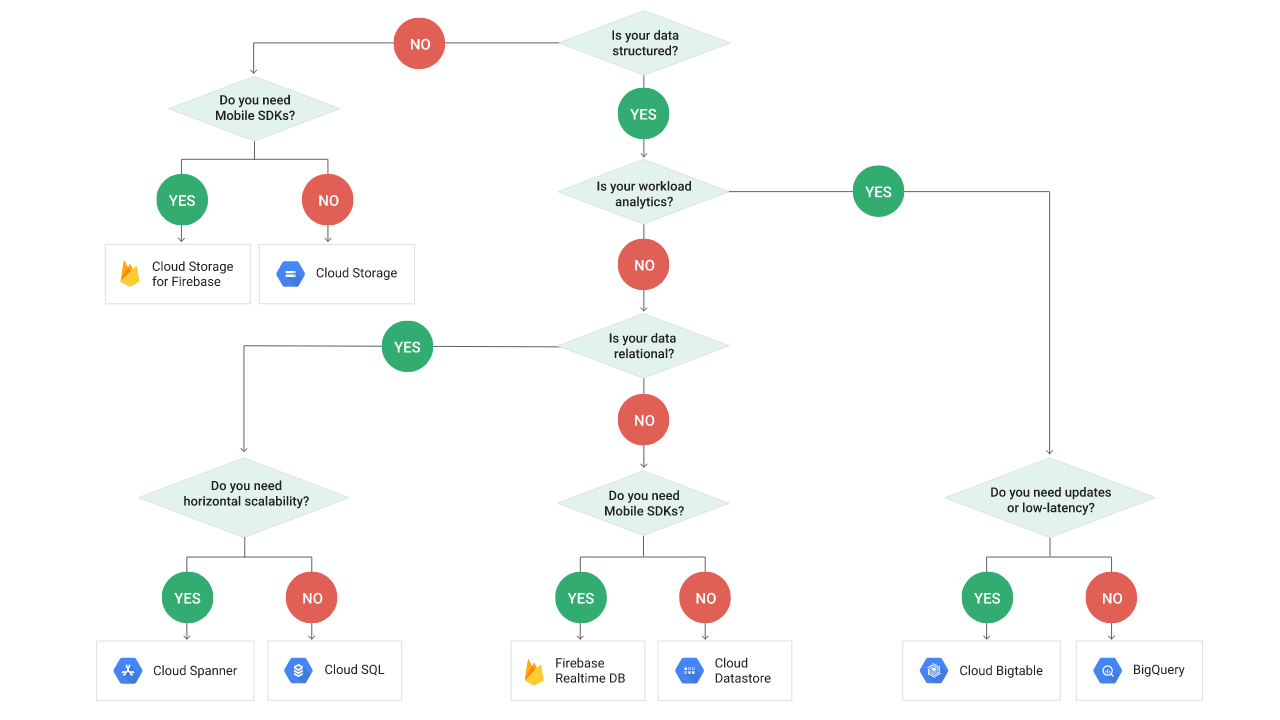
Need some help choosing?
If it's still not
clear which is the best option for you, Google also made a complete Decision
Tree.